
For my first blog on the new SanjMo.com website, I decided to write about PostgreSQL due to its phenomenal momentum in the market. This feature-rich relational database management system (RDBMS) truly embodies the ethos of open-source.
Its governing body consists of a diverse set of contributors and committers. They don’t belong to any single company as we see in some other products that claim to be open source. So far, the community has attracted over 600 contributors and over 50,000 commits in its 30 years of development. Its licensing is also the most liberal which is why the community is thriving.
The final reason for selecting this topic is that we have seen an increase in momentum for fully managed versions in the cloud.
Let’s first take a look at what is the reason for the momentum behind PostgreSQL, aka, the Linux of databases.
Why PostgreSQL?
PostgreSQL has so many features that entire books have been devoted to this subject. For this blog, I wanted to point out my top three favorites.
- Extensions. It has hundreds of extensions. Developers write extensions in a language of their choice and then enable them using the CREATE EXTENSION command. One of the extensions, PostGIS, is probably the best geospatial system available today. Citus Data built a high-availability extension to allow multiple synchronous instances. Citus Data is now owned by Microsoft. While there is a fully-managed Azure offering (called Azure Database for PostgreSQL Hyperscale), Microsoft also continues to provide this extension as an open-source offering. Finally, TImescaleDB provides a very popular extension to enable time-series data.
- Developer functionality. There are many features that I can cover here but I want to focus on the continuing maturity of the JSON datatype in this developer’s database. Some JSON has existed in PostgreSQL for almost ten years but with every release, it has matured its storage and accessibility. The latest release of PostgreSQL 14 beta 2 furthers the user experience aspects. Another developer-friendly aspect is the support for many languages such as Java, R, Python, .Net, C++ and Go. PostgreSQL has many procedural extensions such as PL/TCL, PL/Perl, PL/Ruby and PL/Python.
- Infrastructure modernization. The deployment and maintenance process of PostgreSQL gets a huge shot in the arm with all the developments in the Kubernetes space. On one hand, the deployment is becoming more declarative through the use of YAML files. On the other hand, Kubernetes makes the installation self-healing. If it detects a fault, it can automatically start up a new instance of the component with no manual intervention.
Like many of you, I got my start in Oracle and hence, there are many things that baffle me when using PostgreSQL. Let’s see those next.
Differences with Oracle
When Oracle was building some of the new features, it had to create new approaches as standards didn’t exist. Later ANSI caught up and created standards but they may sometimes differ from how Oracle does things.
Anyone who has ever had the pleasure of migrating from Oracle to PostgreSQL has to handle these nuances. And there are many. For this blog, I have listed three of my favorites as follows:
- Commands. In Oracle, a SELECT statement must have a FROM clause even if you don’t need it. For example, to get SYSDATE, you need a table. So, Oracle provides a single row and a single column table called DUAL. In PostgreSQL, the FROM clause with a table (e.g., DUAL) is not needed. But, wait. It gets more interesting. In Oracle, a DELETE statement does not need the FROM clause but in PostgreSQL, it is mandatory! Go figure…
- VACUUM. It is analogous to Java’s garbage collection. Oracle doesn’t have this concept. The reason for that is because in PostgreSQL, the SQL DELETE or UPDATE commands logically delete the original row and insert a newly updated row with a new version number. This leads to the problem of ‘dead tuples’ and the space they occupy is referred to as ‘Bloat’. The VACUUM command is used to recover the physical space. Oracle does not store versions of row changes in the table but uses undo_segments to handle changes.
- Data types & indexes. PostgreSQL has far more data types – 64 to be precise. The number data type in Oracle can be migrated to 6 different types – numeric, int, smallint, bigint, real and double precision. Similarly, PostgreSQL has more date and time data types than Oracle. Finally, PostgreSQL has many more types of indexes than Oracle although it lacks bitmap indexes.
There are a slew of Oracle features that are not supported in PostgreSQL such as, synonyms, packages, query hints and join shortcuts using the + sign etc. Similarly, PostgreSQL introduces its own twists such as transactional DDLs which can be rolled back.
PostgreSQL is still lacking core multi-leader write capability and is best suited for transactional use cases and not columnar data warehouse ones. This leads us to explore vendors who have solved many of these limitations.
PostgreSQL Vendor landscape
PostgreSQL is available across many vendors. However, not all distributions are the same. The figure below shows almost two dozen options. These are classified under these three categories:
- Enhanced: The products in this category either package specific configurations or enhance the core functionality which are available as open-source or proprietary extensions on top of the core code. The advantage these products have is that they stay current on the new PostgreSQL versions.
- Fork: The products in this category have added new proprietary functionality which the vendor wants to commercialize by changing the core code. The vendor may decide to contribute it to the open source community. By forking off the main branch of the code, extra effort is needed to rebase to the new versions of the core code.
- Wire-compatible: These products provide wire compatibility to PostgreSQL applications but their core engine does not use PostgreSQL. For example, CockroachDB uses a variant of RockDB as its storage engine.
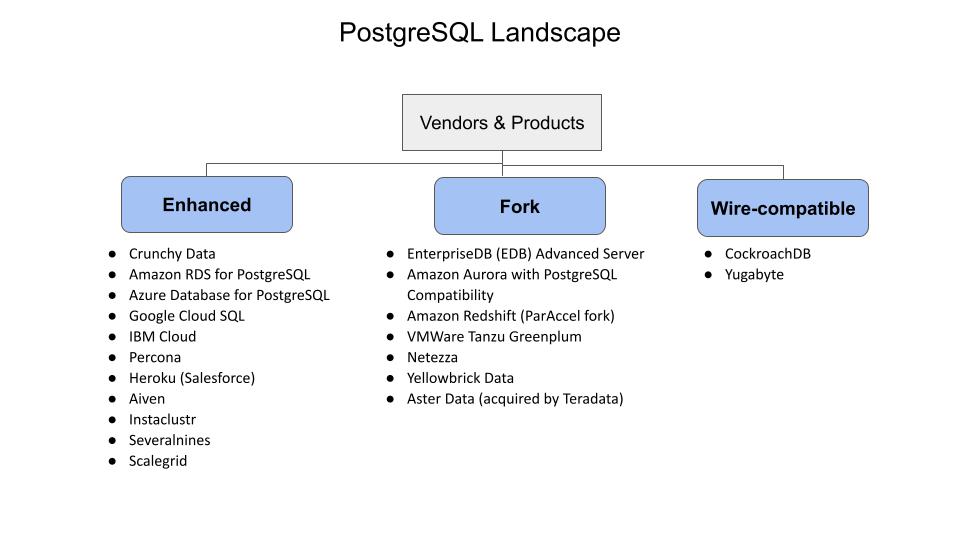
The figure gives a high-level view of the products although some vendors have multiple products. For example, Azure Database for PostgreSQL comes in three options – Windows-based, Linux-based and Hyperscale. Almost all the products mentioned in the figure are primarily focused on constantly enhancing their cloud offerings. This takes us to the next topic on DBaaS.
Why use PostgreSQL DBaaS?
Database as a service (DBaaS) abstracts the management and administration of database deployments in the cloud and has the potential to be more cost efficient compared to an Infrastructure-as-a service (IaaS) solution where a database is installed and maintained on a pre-provisioned set of dedicated instances.
Some of the database administration tasks that are handled by DBaaS include:
- Infrastructure build. These tasks include racking, stacking of the equipment, setting up power, networking, HVAC and other physical deployment tasks.
- Infrastructure maintenance. This includes steps pertaining to installing, patching and upgrading servers, operating systems and also the DBMS software.
- Database administration. This includes automatic/manual backups, high availability and disaster recovery setup, scaling up/down/out/in.
Each product mentioned in the above figure comes with its own pros and cons. The list of criteria to evaluate the right option is based on many factors, some of which include:
- Multi cloud option versus a native cloud offering which is integrated with the ecosystem and hence has the perception of vendor lock-in.
- Cost is of course a huge factor. It is a myth that DBaaS products alleviate the need to configure and performance tune the database. At least for PostgreSQL, adjusting configuration parameters can have a significant effect on the cost of running the database. Perform benchmarks on different instance types to gauge the cost for your particular use cases, workloads and desired performance SLAs. In the cloud, cost unpredictability concerns the management more than the actual cost of the service.
- Scalability, availability, disaster recovery, backups should be carefully assessed. Automatic versus manual scaling of compute, storage and connections can vary widely between various DBaaS offerings. The DBaaS vendors should offer automatic backups with point in time recovery (PITR). High availability (HA) options include read replicas across zones and partitioning / sharding. Disaster recovery (DR) options include multi-AZ or cross-region replication. Check with the product to see whether they offer synchronous or asynchronous replicas and the latency between the primary and secondary.
- Security is paramount and every vendor has the basics covered but some offerings run inside customer VPCs and some don’t. And some have certain required certifications such as HIPAA while others don’t.
- Supported versions and upgrade strategies are critical to evaluate. Some vendors make new versions available within weeks of the open-source version release while some may be a year behind. The ones that are late in upgrades may have known critical vulnerabilities and exposures (CVEs). The next thing to assess is how the upgrades are performed. The most ideal is ‘in-place’ upgrades or rolling upgrades and the least desirable are ones that require a production database to be down to use pg_dump and pg_restore.
- Support quality of the vendor is a key differentiator. This includes their depth of PostgreSQL knowledge and the level of commitment in the community. This manifests in their ability to fix bugs in a timely manner. Some DBaaS vendors even provide white glove service which extends database support to even application development and can help with performance tuning.
Once the right target database is picked the next thing is data migration.
Migration to PostgreSQL
Lift and shift approach is often used to migrate from an on-premises self-managed DBMS to the cloud. This is the fastest way but this is an IaaS option and it doesn’t take advantage of the DBaaS capabilities. Also, this migration is often performed for homogenous or like-to-like products such as on-premises PostgreSQL to Azure Database for PostgreSQL Hyperscale.
Heterogeneous migrations involve different sources and targets such as migrating on-premises PostgreSQL to Amazon RDS for MySQL. Data migrations is a big topic and we will reserve it for a future blog but to give an example of some native tools involved, please see the figure below.
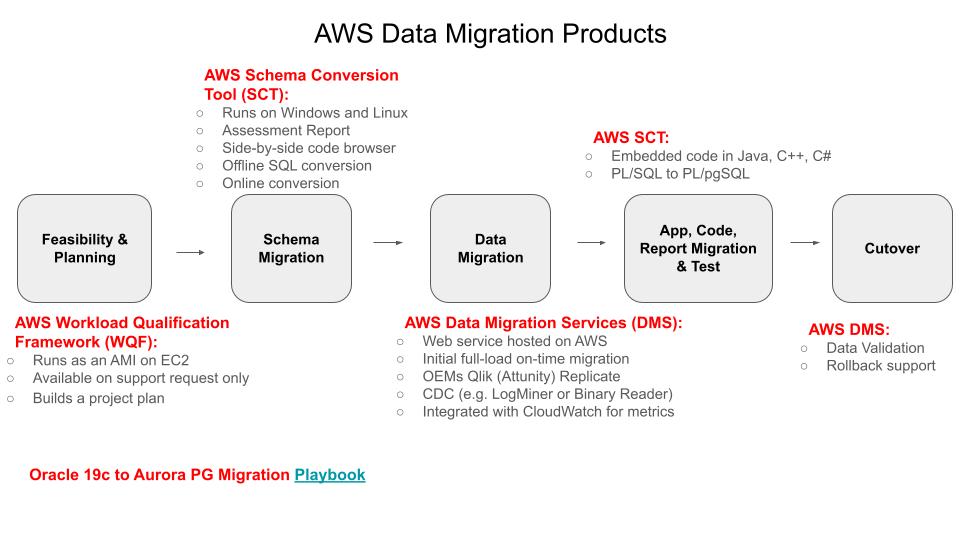
This figure shows the AWS data migration products because they are among the most mature and complete. AWS is reporting they have done over 450,000 total database migration to AWS. This number includes homogenous and heterogenous migrations of all kinds.
There are many other fine data migration products available in the market. That is a topic for a future blog.
Conclusion
This white paper gives a glimpse of the vast and exciting world of open-source PostgreSQL. Stay tuned as PostgreSQL 14 goes GA later this year.
And a few new DBaaS offerings are in the works. These will launch later this year. Expect to read more on the exciting new additions in a subsequent blog on PostgreSQL.
